SREのない国で、SREのマインドセットを広げていく
はじめに
はじめまして。ぺんた(@plageoj)と申します。
2023年、株式会社Faber Companyに入社し、SRE チームがない中で、プロダクトの信頼性を高める活動を続けてきました。 2025年1月からは、ベトナムのホーチミンシティにある子会社 Faber Vietnam で、現地のエンジニアたちと一緒にプロダクト開発に関わっています。
エンジニアたちと対話を重ねていく中で、SREたちが当たり前に使っている共通語彙、例えば SLI/SLO、ポストモーテム、トイル、といった言葉がなかなか通じないことに気づきました。
専門用語に頼らず、地道にコミュニケーションの壁を乗り越えてきた経験は、他分野のエンジニアやマネージャーと話すにあたってのヒントになるのではないかと思い、今回寄稿させていただきました。
ベトナムにおけるSREの現状
ベトナムにおける SRE の需要を知るには、求人情報を見るのが一番手っ取り早いでしょう。LinkedIn で “SRE” を検索すると、ベトナム国内では40件ほどの求人が見つかります。
そのほとんどは外資系企業の現地求人や、全世界を対象としたリモート求人です。
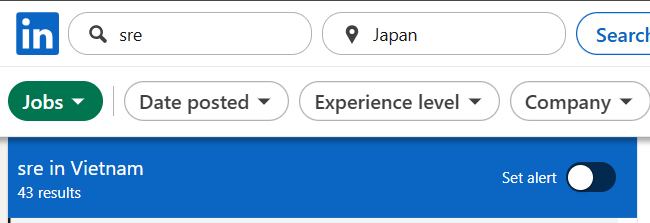
対して日本では1,000件を超える求人が見つかります。日本では LinkedIn は求職プラットフォームとしてはそれほどメジャーではないですが、これだけでも需要に大きなギャップがあることがわかります。
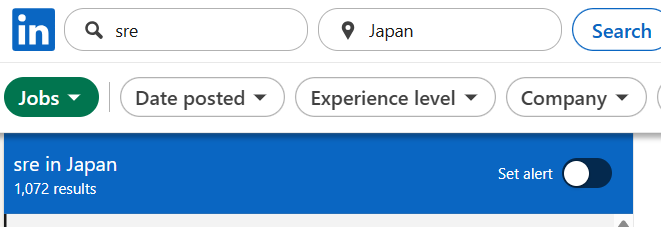
ベトナムのIT産業は SIer による受託開発が中心で、サービスを継続的に改善するための SRE チームを持つ企業はまだ少数派です。SRE というロール自体に対して、企業側・エンジニア側双方の認知度がまだまだ低いことが窺えます。
いわゆるSRE本のような書籍も、ベトナム語には翻訳されていないのが現状です。SREの概念を学ぶためのリソースは、英語の書籍やブログ記事に頼るか、主にクラウドベンダーが出している機械翻訳のドキュメントを読むしかありません。
Site reliability engineer (SRE) là một khái niệm không quá phổ biến ở Việt Nam, kể cả với những anh em làm lập trình, kỹ sư hay làm việc với hệ thống công nghệ thông tin. Thực tế thì vai trò của SRE thường thể hiện nhiều hơn trong các tổ chức có sản phẩm cần vận hành trên một hệ thống lớn, đòi hỏi sự ổn định cao. Đối với các công ty có quy mô vừa và nhỏ, công việc của một SRE có thể được đảm nhiệm bởi một kỹ sư hệ thống, hay một DevOps; vì thế mà nhiều anh em chưa phân biệt được 2 khái niệm này với nhau.
(訳)Site reliability engineer(SRE)は、ベトナムではそれほど一般的な概念ではありません。プログラマーやエンジニア、ITシステムに携わる人たちでさえ、あまり馴染みがないのが現状です。実際、SREの役割は大規模なシステムで高い安定性が求められるプロダクトを運用する組織でこそ発揮されます。中小規模の企業では、SREの業務はシステムエンジニアやDevOpsが担うことが多く、両者の違いを明確に区別できていない人も少なくありません。
出典: SRE là gì? SRE và DevOps khác nhau như thế nào? - topdev.vn
開発基盤の改善からスタート
SRE の代わりにシステムの信頼性確保や運用自動化に取り組んでいるのが DevOps エンジニアです。ベトナムにおいても、DevOps エンジニアは、開発と運用の両方に関わり、CI/CD パイプラインの構築や、Infrastructure as Code の推進、監視システムの導入などを行う役割として認識されています。
他社では DevOps チームを設置し、専任のエンジニアがインフラの設計や運用を行うケースが多いようです(DevOpsチームを「DevOpsチーム」と呼ぶのはやめるべき? というような議論もあり、個人的にはこの考え方に同意しますが、ベトナムでは一般的でないようです)。
当社には DevOps の専業チームはありませんが、主にデプロイ作業を行うエンジニアに DevOps の知識をつけてもらうのは、SRE の手法を取り入れるベースとして効果的でした。
SRE というと、SLA や SLI の制定をやりたくなってしまいますが、これには顧客やビジネス側を巻き込む必要があります。品質に投資をしてもらうため、まずは手元の開発基盤を改善し、エンジニアの生産性・プロダクトの安定性という実績を示すことから始めました。
会社で依頼していた外部の技術アドバイザーにも相談し、開発リソースを品質向上に振り向ける了承を経営層からもらうことを手伝ってもらいました。
不要機能の削除
入社当時、私が担当したプロダクトは Java Servlet + jQuery で構築されている Web アプリケーションで、Java が21万行、JS が45万行ほどの規模でした。開発開始から約10年が経過し、古い機能のコードが残っていたり、新旧の書き方が混在(例えば、メニューヘッダーを描画するコードは3バージョンあった)していたりしていました。
日次でコード行数を計測・可視化し、使われていない不要なライブラリを削除したり、古い機能を削除したりすることで、コードの見通しを改善しました。
当時から機能自体は増えているものの、LOC にして約30%の削減に成功しています。特に JS について、ライブラリの読み込みをローカルから CDN ベースに変えることと、ES5 から ES6 へ移行して各所にあったポリフィルを削減できたことが大きく寄与しました。これは保守性だけでなく、パフォーマンスの改善にもつながります。
静的解析の導入
プロジェクトでは2名体制によるコードレビューを行っていますが、レビューの質はエンジニアの経験に依存していました。また、シニアエンジニアにレビューリクエストが集中する傾向があり、1ヶ月に100本を超える PR をレビューするメンバーも出てきていました。 レビューの待ち時間が長くなるとレビュー品質が保てなくなり、チェックをすり抜けたバグのあるコードが本番環境で問題を起こし、さらにその対応に時間をとられて不完全な状態でリリースしてしまう悪循環も発生しました。
最低限のコード品質を担保し、レビューの負荷を軽減するため、Java に対して SpotBugs、JS に対して ESLint を導入し、コードの静的解析を行うようにしました。最初はかなりの数の警告が出ましたが、ジュニアエンジニアのオンボーディングとして SpotBugs の警告を解消してもらうことで、彼らにコード品質を改善する中心的な役割を担ってもらうことができました。
この構成は後に SonarQube Cloud へ移行し、チーム全体でコード品質を保っています。
静的テストの CI 実行
CI の整備もイチから始まりました。当初自動テストのカバレッジは 0.2% ほどで、各開発者のローカル環境でしか実行しておらず、ビルド速度を理由にテスト実行をスキップすることも行われていました。
CI でのテストを整えるべく、GitHub Actions を使って、PR 作成時に自動でテストが実行されるようにしました。ほとんどテストが整備されていなかったことが逆に幸いして、最初から「テストが通らなければマージできない」を徹底することができました。
現在カバレッジは 16% まで改善しています。
ログを見る習慣から始まる、可観測性への挑戦
開発基盤の改善成果を数値として示すことで、これまで開発した機能の量やスピードで評価されてきたエンジニアたちに、少しずつ「品質」の重要性を理解してもらうことができました。
次に着手したのが、プロダクトのログまわりの運用の改善です。当初、ログは EC2 内のファイルに出力されるのみで、サーバーにアクセス権のある一部のエンジニアしか見られない状態でした。また、エラーの種類や発生箇所によってログの書き出し先が異なり、一貫したログの分析が困難で、アプリケーションの構造を深く理解していなければログの意味を把握することができませんでした。このため、障害調査のためにログを見に行くという発想がそもそもないメンバーもいました。
ログフォーマットの統一、出力先の一本化
ログのフォーマットを JSONL に統一し、全ログを CloudWatch Logs に出力するようにしました。また、エンジニア全員に AWS のアカウントを作成し、CloudWatch の検索機能や CloudWatch Logs Insights、Athena などを使ってログを検索・分析できるようにしました。
このことは、インシデント対応や顧客からの問い合わせ対応の効率化という形ですぐに効果を発揮しました。今では複数のチームが毎朝ログやメトリクスを見る時間を設定しており、問い合わせに頼らず問題を発見するよう努めています。
「調査失敗アラート」の整備
当社で提供している SEO 支援ツールには、スクレイピングや外部 API の呼び出しを伴う「調査」機能が多数あります。これらの機能は、外部の仕様変更やレートリミットなどで動作しなくなることがしばしばあり、都度問い合わせをいただいて修正する運用になっていました。問い合わせがあるということはもちろん、問い合わせをしないで利用を諦めてしまうユーザーもいたであろうことが予想されます。
システム内部の例外だけでなく、ユーザー側からみた調査の成功/失敗を記録し、失敗率が一定を超えた場合にアラートを発報するようにしました。アラートを起点にログを調査し、素早く問題に対処するだけでなく、顧客からの問い合わせが来る前にカスタマーサポートに情報を流せるようになりました。
ポストモーテムの実施
インシデントの経緯や対処を記録する「インシデントレポート」として、ポストモーテムを導入しました。ここは「ポストモーテム」という単語が通じず、単純にレポーティングをするだけではないという葛藤もありつつも、インシデントレポートという言葉を選択しました。
まずは事実の記載から始め、徐々に原因を個人に求めないことや有効性のある改善策を考えることに慣れてもらいました。再発防止策を相互にレビューすることで、直接インシデント対応に関わらなかったメンバーにも学びを共有できるようにしました。
対策実施後の効果検証や、インシデント対応フローにはまだ改善の余地があり、鋭意取り組んでいるところです。
デプロイフローの改善
手作業による複雑なデプロイ作業を改善するのも大きな課題でした。長年の運用で複雑化したデプロイフローの作業項目は30を超え、本番 DB で SQL を手動実行するなどリスクの高い作業や、LB からデタッチしたサーバーからユーザーがいなくなるまで待つなど時間のかかる作業もありました。
これらの作業は経験のあるシニアエンジニアにしかできず、彼らの時間を奪う要因となっていました。
EC2 → ECS への移行
アプリケーションをコンテナ化し、ECS へ移行することで、デプロイフローを大幅に簡略化しました。デプロイ手順は4ステップに集約され、1時間以上かかっていた時間も20分程度に短縮されました。
またオートスケーリングやヘルスチェックを活用することで、可用性と耐障害性が向上し、問題が起こったときに迷わずコンテナを再起動できるようになりました。
デプロイの自動化
ECS の導入により手順が簡略化されたことで、GitHub Actions や CodeDeploy を使ったデプロイの自動化にも着手できるようになりました。現在は完全な自動化には至っていないものの、ステージング環境へのデプロイを誰でも実行できるようになり、Slack への通知を活用することで手作業に伴う待ち時間を削減しています。
SREのマインドセットを広げるために
「SRE の概念を理解する」ことを要求するのではなく、目の前の課題をどのように技術で解決できるかを丁寧に議論することで、少しずつシステムを改善し、同時にチームの運用能力を高めていくことができました。
また、この取り組みがどのような価値をもたらすか経営陣やマネージャー層に説明することにも、ベトナム人エンジニアとの対話と同じくらい力を入れました。ワークフローを変えることでどれだけ生産性を上げられるのか、どれだけの時間を節約できるのか、そして今後の経営方針にどうついていくのか、ストーリーを描きながら説明していきました。社外への発信にも力を入れ、ブログ記事やセミナー登壇を通じて、同じように SRE チームの立ち上げに取り組むエンジニアたちと情報を共有しています(本記事もその一環です)。
本記事で取り上げた具体的な手法は一例に過ぎませんが、それぞれのチームやプロダクトが抱えている課題に正面から向き合い、課題を解消することでどうビジネスに貢献できるのかを丁寧に説明していけば、SRE という言葉を使わなくても SRE のマインドセットを広げていくことができると信じています。