非決定的なワークロードの信頼性を考える
はじめに
こんにちは。Datadog Japan で Sales Engineer をしている 木村健人(AoTo)です。
2025年6月現在、大規模言語モデル(Large Language Model, LLM) の進化により SRE の取り組みに LLM を活用し既存の AIOps を高度化する試みが見られ初めています。本マガジンの巻頭言 にも、「SRE × AIの事例」について語られています。 さらに、「AI エージェントの年」とも呼ばれる2025年に、こうした潮流の象徴として Microsoft は Azure App Service のプラットフォーム上に SRE エージェントを提供することを発表しました。 このように SRE の役割を高度化させるために生成 AI、特に LLM を活用する方法は既に多く紹介されています。
一方で、生成 AI のような「非決定的なワークロード」に SRE のプラクティスを適用し信頼性を確保する事例は未だにほとんど見られません。 このような背景から本記事では、生成 AI のような非決定的なワークロードの信頼性を従来の SRE のプラクティスから考察し提言します。ここでは、信頼性・SLI/SLO について考察しますが、その後の運用・エラーバジェット・バーンレートアラートなどは触れません。
「非決定的なワークロード」とは、特定の状況・要素によって結果が完全に決まらない状態や性質を持つシステムの処理を指します。つまり LLM チャットボットを例にすると、特定のプロンプトに対しての回答が一意に定まらないことなどが挙げられます。
免責事項
本記事内で説明される内容は、筆者個人の経験に基づく意見・考え方の一例であり、所属組織を代表するものでは一切ございません。
生成 AI の特性と信頼性
一般的なシステムやサービスは LLM のモデル自体を開発し運用することはほとんどないと言えます。 Google の Gemini, OpenAI の ChatGPT, Anthropic の Claude, xAI の Grok, Amazon の Nova, Meta の Llama, DeepSeek など…これらを全く耳にしたことのないエンジニア・プログラマを探す方が難しいでしょう。
このような前提から、SRE が考慮するべきなのは LLM や画像生成, マルチモーダルな生成 AI の基盤モデル(FM)自体の信頼性ではないと言えます。 SRE は上記のような AI 企業が提供する高パフォーマンスな基盤モデル(FM)を、クラウドサービスが提供する生成 AI のマネージドサービス上の API を通して利用する上での信頼性を考慮することが重要です。 生成 AI のマネージドサービスとは Amazon Bedrock, Azure OpenAI, Google Cloud Vertex AI のような、基盤モデルの統合 API を提供するサービスのことを指します。
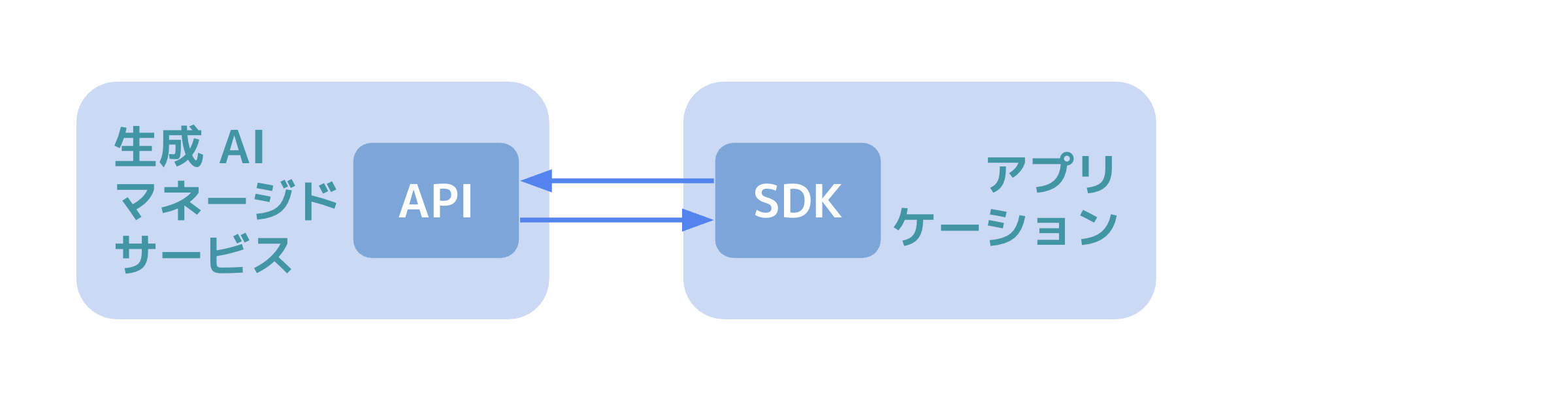
こうした構造からも、通常の SRE のプラクティスで用いられる RED メトリクス・USE メソッド・ゴールデンシグナルなどを元に SLI/SLO を設計することが重要になります。 そして何よりも同時に生成 AI の特性である「非決定性」を考慮しなければ、生成 AI を利用するアプリケーションの信頼性を測定できません。
例えば、手元の ChatGPT-4o のチャットボットでは「こんにちは」と入力すると「こんにちは!今日はどんなお手伝いをしましょうか? 😊」と返答します。続けて「こんにちは」と入力すると「こんにちは、またお会いできてうれしいです!😊 何か聞きたいことや相談したいことがあれば、何でもどうぞ。」と返答が変化します。別のモデルでも返答が異なるでしょうし、同じモデルでも毎回少しづつ返答が変化するはずです。こうした LLM をはじめとする「非決定的」な特性においては、どのような返答つまり出力を元に信頼性を測定するのでしょうか。
一般的に SRE の文脈における信頼性は「システムが求められる機能を、定められた条件の下で、定められた期間にわたり、障害を起こすことなく実行する確率」のように定義されます。 生成 AI のような「非決定的」な要素を含むシステムは、従来のシステムと比較して「求められる機能」が異なるはずです。利用者は単一の入力に対して一意の出力を期待している訳ではなく、「人間にとって有効な」回答や情報が返されることを求めています。

そもそも利用者の目線から考えると、こうした内部の挙動や生成 AI の存在はブラックボックスとして捉えられます。その上で、利用者が生成 AI を利用するシステムに求めることは「人間のタスクをどれほど代替し、それ以上の効果を得られるか」とまとめられるかもしれません。 今回はこうした前提で信頼性や SLI/SLO を測定するために、前回の『SRE Magazine 007号』でご紹介した『Google が実践する最先端の SRE』に取り入れられている手法である STAMP/STPA を利用してみましょう。
LLM を利用するシステムがハザード状態となるシナリオを考えてみましょう。ここではすべての場合で、「こんにちは」と入力する場合に単純化して考察をします。 まず初めに想像できるハザードは、「こんにちは」と入力したのに何の返答も得られないケースです。これはシステム内のどこかしらで、「適切な入力やそれに伴う処理が与えられなかったハザード」です。 次に、「こんにちは」という入力に「こんばんは。東京都千代田区はどのような天気ですか?」と返ってきたらどうでしょうか。入力時刻やユーザーの位置情報など、利用者が意図しない内容を考慮した返答は「想定しない情報が入力に与えられるハザード」です。 他にも、返答に自然言語以外の人間が理解できない文字列が含まれる「誤った出力を利用者に表示してしまうハザード」や、単に返答が遅く待ちぼうけとなる「出力が生成される時間が遅すぎるハザード」も考えられます。
ハザードの要因分析を元に生成 AI を利用するシステムに求められるもの整理すると、以下のような観点の信頼性が求められます。
- 出力の一貫性(Consistency)
- 出力の精度(Accuracy)
- 出力の即時性(Latency, Response Time)
- サービスの可用性(Availability)
出力の一貫性・精度は生成 AI の出力の内容から信頼性を測定する必要があるのに対し、出力の即時性・サービスの可用性は一般的な SRE の信頼性と同じ RED メトリクスを元に信頼性を測定できます。 ここからは、前者の2点についての信頼性の測定方法となる SLI/SLO を考察していきます。
SLI - 非決定的なワークロードの指標
信頼性を測定するためには、その目標となる値を測定するための尺度である サービスレベル指標(Service Level Indicator, SLI) が必要です。 出力の一貫性・精度はその出力自体の内容はもちろん、入力の内容に照らし合わせることで出力の一貫性や精度を評価できます。
こうした前提から、SLI を定義する上で重要となるのがプロンプト管理です。 プロンプト管理はさまざまな場面で利用されますが、主に LLM への入力としてのプロンプトとその出力と共に記録することを指します。SRE の文脈では記録されたプロンプトの入出力を、一貫性・精度の観点で評価するために利用します。
一貫性の観点では、ある入力に対する出力に一定の内容が含まれているかを評価します。生成 AI の「非決定的」な特性を考慮すると一意の出力は期待できないため、特定の文字列や過去の回答からの乖離を測定します。 精度の観点では、入力に対する出力の真実性・正確性を評価します。評価の方法は、人間によるサムズアップ・ダウン、離脱率などユーザーの行動からの分析、LLM による定量的な評価を行うなど様々な方法が考えられます。
この様に出力の一貫性・精度を評価するためには、評価結果の定量化と評価方法の選定が必要となります。 様々な評価手法の中でも、LLM as a Judge は柔軟に様々な観点の評価を同時に定量化できる手法です。
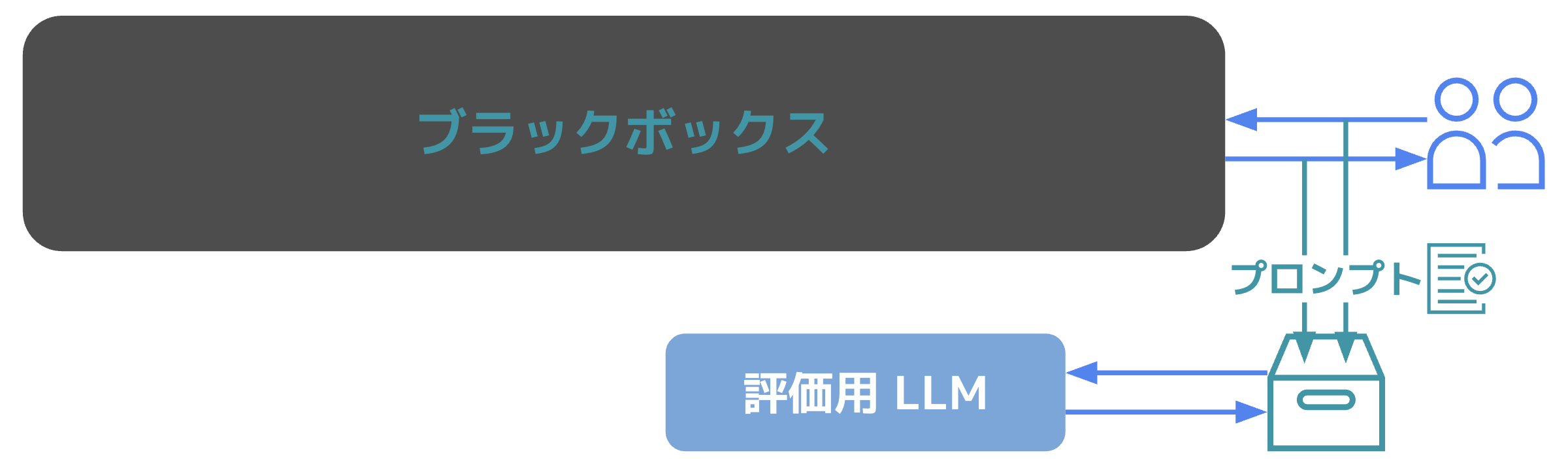
LLM as a Judge は 評価用の LLM とプロンプトを別途用意し、プロンプト管理で保存されている入出力を用いて定量的な点数と共に評価を行えます。これにより、SLI の元となる評価結果が定量的に取得できます。 「非決定的」な出力に対して、決定的な評価を下すことは現実的ではありません。評価にも LLM のような「非決定的」な要素を利用することで、柔軟に様々な評価値を定量化できます。

SLI とは、良いイベントが有効なイベントに占める割合で示されます。 今回の場合、SLI は全出力のうち出力が一定の評価値を超えたもの割合として定義できます。 より数学的に表現をすると、評価値が閾値を超えたイベントの数から全出力の数を割り 100 をかけたものです。
こうした出力の一貫性・精度などの品質に対する SLI と同様に、出力の即時性やサービスの可用性は LLM を提供するマネージドサービスの API への RED メトリクスを元に定義できます。
SLO - 非決定的なシステムの信頼性水準
前述のように、出力の一貫性・精度に関する SLI は LLM によって評価された定量値を用いて定義することができました。 この SLI から目標値である サービスレベル目標(Service Level Objective, SLO) を定義する際も、生成 AI の「非決定的」な特性に注意が必要です。
SLI に定義するために、LLM が評価した定量値は厳密な尺度ではありません。特に、プロンプトやモデルの変化によってその値はある程度変化します。 こうした「非決定的」な特性を持つ定量値を扱う場合、厳密な SLI の閾値や SLO の目標値は過剰な信頼性設計となり得ます。
例えば、出力の一貫性・精度の評価値に対して、良いと評価する閾値を100点中90点とした場合、何らかの評価プロンプトの変更で同一の内容であっても90点を上回りづらい結果が出続ける。 この場合、評価プロンプトに対して必ず SLI が定義する「良いイベント」にあたる評価の閾値を厳密に考慮することが望ましいです。
SLI の設定がきちんとされていれば、通常の SLO の場合と同様に何らかのユーザーストーリーや根拠に即して SLO の目標値を定めれられます。 しかし前述の通り、実際の出力の品質が変化していないにも関わらず評価値が変化する可能性があります。そのため、SLO はこうした特性を考慮した 99.9% や 99.99% のような厳密な値を取らず、90% や 95% 程度の値を定めることが好ましく考えられます。
このように「非決定的」なワークロードはその特性を考慮して、SLI の元となる指標を定量化し、適切な水準の SLO を設定することが必要です。
おわりに
本記事では、生成 AI の特徴である「非決定的なワークロード」に SRE の観点から信頼性をどのようにに担保するかを考察しました。 これまでの SRE のプラクティスは主に、予測可能かつ一意に結果が決まるワークロードを対象として発展してきました。しかし、生成 AI の普及により、「非決定的」な特性を持つシステムに対しても、従来のプラクティスを適用しながら、新しい指標や評価基準を設けて対応する必要性が高まっています。
今回、SLI/SLO 設定の難しさとその解決方法として、プロンプト管理や LLM as a Judge という手法を提案しました。 これらの手法はまだ発展途中ですが、非決定性を前提とした柔軟な評価方法を導入することで、生成 AI を利用したシステムにおいても信頼性を高めることが可能になるのではないでしょうか。
今後さらに生成 AI を活用したアプリケーションやシステムの需要が高まる中で、SRE の担う役割や責務も変化していくと考えられます。 本記事が生成 AI を活用するエンジニアや SRE にとって、新たな信頼性への取り組みの一助となれば幸いです。