SLOベースの監視は廃れるのか
SREといえば、SLOベースの監視
Googleが体系化して広めたSREのプラクティスのひとつに、SLOベースの監視があります。SRE Magazineの読者には説明不要かもしれませんが、以下のような手法です。
- サイトのサービスレベル目標 (SLO) を定義する(例:月間のリクエスト成功率が99.9%以上)
- SLOから導かれるエラーバジェット(例:月間のエラー率が0.1%未満)の消費速度を監視する
こうしたSLOベースの監視は、DatadogやNew Relicなどのモニタリングツールにも基本機能として組み込まれています。もはやデファクトスタンダードな手法といえるでしょう。
この手法には筆者も共感し、勤務先のサイトの信頼性をAWSで監視しています。詳しくは、AWSのウェブマガジン「builders.flash」に寄稿した「自作で大満足 ! AWS だけで理想の SLO 運用を実現した方法」をご覧ください。
ところが、です。
GoogleのSREが示した「SLOの限界」
ふとしたきっかけ1で筆者は、GoogleのSREの方々がSLOに批判的な見解を示していることを知りました。具体的には、Narayan Desai氏が中心となっている以下のリソースにおいてです。
- Principled Performance Analytics(SREcon22 Americasでの講演)
- Rethinking SLOs(Google SRE Prodcastでのエピソード)
特に前者では「SLOs aren’t feasible」(SLOは実現不可能)という強い表現も使われています。
Desai氏らは何を問題視しているのでしょうか。筆者の理解では、彼らの主張するSLOの限界は以下のようなものです。
- エラーという曖昧なデータに基づいている
- メンテナンスが難しい
それぞれ、少し詳しく見てみましょう。
1. エラーという曖昧なデータに基づいている
彼らは、SLOがエラーという曖昧なデータに基づいていると批判しています。特定のイベントがエラーにあたるかどうかは人間が定義せざるをえず、その定義が適切である保証はありません。したがって、ある状況がエラーとして過大評価されることもあれば、過小評価されてしまうこともあるわけです。言われてみれば、たしかにそう思えます。
2. メンテナンスが難しい
さらに彼らは、SLOのメンテナンスの難しさも指摘しています。SLOは定義して終わりではなく、定期的に見直さなければなりません。しかし、どのような頻度で見直すべきなのか、また、どのように値を調整すべきなのか、標準的な指針は存在しない状況です。この点も、大きな課題だといえるでしょう。
「2σテクニック」という代替案
SLOに限界があるとすれば、どうしたらよいのでしょうか。
Desai氏らは「2σテクニック」という代替案を講演で披露しました。簡単にいえば、過去のパフォーマンスの平均値との差異が「2σ」を超えている応答を異常とみなす手法です(σは標準偏差)2。そして、異常な応答が全体の10%を超える場合にアラートを発します。
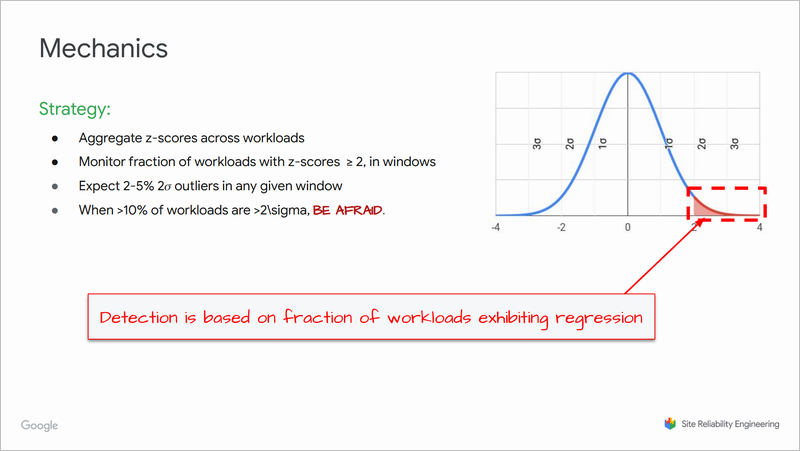
2σテクニックの仕組み(出典:Principled Performance Analytics)
この手法であれば、パフォーマンスという明確なデータに基づく形になりますし、メンテナンスも不要そうです(過去のパフォーマンスから統計的なベースラインを自動計算すれば済むため)。
さらに、この手法には、パフォーマンスの悪化に早く気づきやすいメリットがあると彼らは言います。過去の障害事例でテストしてみたところ、もし2σテクニックを導入していれば、異変に18時間も早く気づけたとのことです。
偽陽性も少なく、9か月の本番運用で1件のみだったとも言っています。メリットだらけのように見えますね。
SLOベースの監視は廃れるのか
では今後、SLOベースの監視は廃れるのでしょうか。
筆者は、しばらくは廃れないと考えます。2σテクニックは2022年の講演で披露されましたが、その後、続報やツール化といった動きが見られません。導入指針が具体的に示されないと、他の組織による採用検討は難しいでしょう。GoogleのSREたちも、おそらく試行錯誤を続けていて、まだSLOベースほどの体系化には至っていないのだと思います。
とはいえ、2σテクニックが面白いアプローチであることは間違いありません。今後の進展に注目しましょう。実際にどんな結果になるかはともかく、GoogleのSREたちが自ら体系化したプラクティスを批判的に乗り越えようとする姿には、学ぶべきところが多いと感じます。
-
「シネマ de LT会#2 〜Back to the Screen〜」での発表内容を考える際に見つけました。資料の「8万デプロイ」にも、本稿のエッセンスが含まれています。 ↩︎
-
平均値や標準偏差は、似たような特性を持つワークロード群(コホート)ごとの過去の履歴から算出します。 ↩︎